Linux 作为一个多任务操作系统,将每个 CPU 的时间划分为很短的时 间片,再通过调度器轮流分配给各个任务使用,因此造成多任务同时运行的错觉。
为了维护 CPU 时间,Linux 通过事先定义的节拍率(内核中表示为 HZ),触发时间中断,并使用全局变量 Jiffies 记录了开机以来的节拍数。每发生一次时间中断,Jiffies 的值就加 1。
节拍率 HZ 是内核的可配选项,可以设置为 100、250、1000 等。不同的系统可能设置不同数值,你可以通过查询 /boot/config 内核选项来查看它的配置值。
同时,正因为节拍率 HZ 是内核选项,所以用户空间程序并不能直接访问。为了方便用户空间程序,内核还提供了一个用户空间节拍率 USER_HZ,它总是固定为 100,也就是 1/100 秒。这样,用户空间程序并不需要关心内核中 HZ 被设置成了多少,因为它看到的总是固定值 USER_HZ。
Linux 通过 /proc 虚拟文件系统,向用户空间提供了系统内部状态的信息,而 /proc/stat 提供的就是系统的 CPU 和任务统计信息。比方说,如果你只关注 CPU 的话,可以执行下面的命令:
1
2
3
4
5
6
|
$ cat /proc/stat|grep ^cpu
cpu 17631119 11049 10800374 123865682 141642 0 273886 0 0 0
cpu0 4497194 2529 2742844 30789756 32209 0 67782 0 0 0
cpu1 4317177 3569 2657864 31145851 29308 0 68306 0 0 0
cpu2 4497074 2504 2739538 30798541 30448 0 65961 0 0 0
cpu3 4319672 2446 2660126 31131534 49675 0 71836 0 0 0
|
这里的输出结果是一个表格。其中,第一列表示的是 CPU 编号,如 cpu0、cpu1 ,而第 一行没有编号的 cpu ,表示的是所有 CPU 的累加。其他列则表示不同场景下 CPU 的累加 节拍数,它的单位是 USER_HZ,也就是 10 ms(1/100 秒),所以这其实就是不同场景下的 CPU 时间。
cpu 使用率常见指标
-
user(通常缩写为 us),代表用户态 CPU 时间。注意,它不包括下面的 nice 时间,但包括了 guest 时间。
-
nice(通常缩写为 ni),代表低优先级用户态 CPU 时间,也就是进程的 nice 值被调整 为 1-19 之间时的 CPU 时间。这里注意,nice 可取值范围是 -20 到 19,数值越大,优 先级反而越低。
-
system(通常缩写为 sys),代表内核态 CPU 时间。
-
idle(通常缩写为 id),代表空闲时间。注意,它不包括等待 I/O 的时间(iowait)。
-
iowait(通常缩写为 wa),代表等待 I/O 的 CPU 时间。
-
irq(通常缩写为 hi),代表处理硬中断的 CPU 时间。
-
softirq(通常缩写为 si),代表处理软中断的 CPU 时间。
-
steal(通常缩写为 st),代表当系统运行在虚拟机中的时候,被其他虚拟机占用的 CPU 时间。
-
guest(通常缩写为 guest),代表通过虚拟化运行其他操作系统的时间,也就是运行虚 拟机的 CPU 时间。
-
guest_nice(通常缩写为 gnice),代表以低优先级运行虚拟机的时间。
事实上,为了计算 CPU 使用率,性能工具一般都会取间隔一段时间(比如 3 秒)的两次 值,作差后,再计算出这段时间内的平均 CPU 使用率,即

这个公式,就是我们用各种性能工具所看到的 CPU 使用率的实际计算方法。
怎么查看cpu使用率
top 和 ps 是最常用的性能分析工 具:
top
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
# 默认每3秒刷新一次
$ top - 10:00:53 up 4 days, 16:38, 3 users, load average: 1.42, 1.11, 1.03
Tasks: 379 total, 1 running, 324 sleeping, 0 stopped, 0 zombie
%Cpu0 : 9.2 us, 10.2 sy, 0.0 ni, 80.6 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu1 : 12.3 us, 7.4 sy, 0.0 ni, 79.9 id, 0.4 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu2 : 11.9 us, 9.5 sy, 0.0 ni, 78.6 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu3 : 12.2 us, 10.5 sy, 0.0 ni, 77.4 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 8071876 total, 194596 free, 2879060 used, 4998220 buff/cache
KiB Swap: 0 total, 0 free, 0 used. 5102912 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
4040 root 20 0 1942132 148460 13756 S 11.3 1.8 1024:33 kubelet
907 root 20 0 70804 5360 4424 S 10.0 0.1 487:59.20 systemd-logind
54 root 20 0 0 0 0 S 5.3 0.0 21:43.42 kswapd0
2425 root 20 0 2542804 92016 6664 S 5.3 1.1 358:58.10 dockerd
810 message+ 20 0 52444 5296 2932 S 5.0 0.1 246:41.94 dbus-daemon
1 root 20 0 227876 10608 5732 S 4.0 0.1 198:35.18 systemd
|
空白行之后是进程的实时信息,每个进程都有一个 %CPU 列,表示进程的 CPU 使用率。它是用户态和内核态 CPU 使用率的总和,包括进程用户空间使用的 CPU、 通过系统调用执行的内核空间 CPU 、以及在就绪队列等待运行的 CPU。在虚拟化环境 中,它还包括了运行虚拟机占用的 CPU。
pidstat
下面的 pidstat 命令,就间隔 1 秒展示了进程的 5 组 CPU 使用率,包括:
-
用户态 CPU 使用率 (%usr);
-
内核态 CPU 使用率(%system);
-
运行虚拟机 CPU 使用率(%guest);
-
等待 CPU 使用率(%wait);
-
以及总的 CPU 使用率(%CPU)。
最后的 Average 部分,还计算了 5 组数据的平均值。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
# 每隔1s输出一组数据,共5组
$ pidstat 1 5
Linux 4.15.0-66-generic (tux-pc) 11/04/2019 _x86_64_ (4 CPU)
10:03:38 AM UID PID %usr %system %guest %wait %CPU CPU Command
10:03:39 AM 0 1 0.98 0.98 0.00 0.00 1.96 0 systemd
10:03:39 AM 0 8 0.00 0.98 0.00 0.98 0.98 2 rcu_sched
10:03:39 AM 103 810 1.96 0.00 0.00 1.96 1.96 0 dbus-daemon
10:03:39 AM 0 907 2.94 2.94 0.00 0.00 5.88 1 systemd-logind
10:03:39 AM 0 2425 3.92 0.98 0.00 0.00 4.90 0 dockerd
10:03:39 AM 0 3522 0.00 1.96 0.00 0.00 1.96 2 kube-controller
10:03:39 AM 0 3593 9.80 0.98 0.00 0.00 10.78 2 kube-apiserver
10:03:39 AM 0 3870 0.98 0.98 0.00 0.00 1.96 0 etcd
10:03:39 AM 0 4040 12.75 7.84 0.00 0.00 20.59 0 kubelet
10:03:39 AM 0 4651 3.92 0.98 0.00 0.00 4.90 2 kube-proxy
10:03:39 AM 10001 6486 0.98 0.00 0.00 0.00 0.98 0 metrics-server
...
Average: UID PID %usr %system %guest %wait %CPU CPU Command
Average: 0 1 0.98 0.98 0.00 0.00 1.96 - systemd
Average: 0 8 0.00 0.98 0.00 0.98 0.98 - rcu_sched
Average: 103 810 1.96 0.00 0.00 1.96 1.96 - dbus-daemon
Average: 0 907 2.94 2.94 0.00 0.00 5.88 - systemd-logind
Average: 0 2425 3.92 0.98 0.00 0.00 4.90 - dockerd
Average: 0 3522 0.00 1.96 0.00 0.00 1.96 - kube-controller
Average: 0 3593 9.80 0.98 0.00 0.00 10.78 - kube-apiserver
Average: 0 3870 0.98 0.98 0.00 0.00 1.96 - etcd
Average: 0 4040 12.75 7.84 0.00 0.00 20.59 - kubelet
Average: 0 4651 3.92 0.98 0.00 0.00 4.90 - kube-proxy
Average: 10001 6486 0.98 0.00 0.00 0.00
|
cpu 使用率过高怎么办
通过 top、ps、pidstat 等工具,你能够轻松找到 CPU 使用率较高(比如 100% )的进 程。接下来,你可能又想知道,占用 CPU 的到底是代码里的哪个函数呢?找到它,你才能 更高效、更针对性地进行优化。
通过 perf 分析cpu的性能问题
perf 以性能事件采样为基础,不仅可以分析系统的各种事件和内核性能,还可以用来分析指定应用程序的性能问题。
安装
1
2
3
4
|
# yum
$ yum install perf
# apt
$ sudo apt install linux-tools-generic
|
perf top
perf top ,类似于 top,它能够实时显示占用 CPU 时钟最多的函数或者指令,因此可以用来查找热点函数,使用界面如下所示:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
$ perf top
Samples: 583K of event 'cycles:ppp', Event count (approx.): 32449180472
Overhead Shared Object Symbol
4.71% [kernel] [k] update_blocked_averages
2.89% [kernel] [k] do_syscall_64
1.14% [kernel] [k] __entry_trampoline_start
1.13% perf [.] hpp__sort_overhead
1.07% [kernel] [k] syscall_return_via_sysret
1.04% [kernel] [k] cleanup_module
1.00% [kernel] [k] update_load_avg
0.83% perf [.] __hists__insert_output_entry
0.76% perf [.] rb_next
0.68% [kernel] [k] seccomp_run_filters
0.62% perf [.] perf_hpp__is_dynamic_entry
0.55% [kernel] [k] copy_page
0.54% [kernel] [k] __schedule
0.54% dockerd [.] runtime.scanobject
|
输出结果中,第一行包含三个数据,分别是采样数(Samples)、事件类型(event)和 事件总数量(Event count)。比如这个例子中,perf 总共采集了 583K 个 CPU 时钟事 件,而总事件数则为 32449180472
另外,采样数需要我们特别注意。如果采样数过少(比如只有十几个),那下面的排序和 百分比就没什么实际参考价值了。
再往下看是一个表格式样的数据,每一行包含四列,分别是:
-
第一列 Overhead ,是该符号的性能事件在所有采样中的比例,用百分比来表示。
-
第二列 Shared ,是该函数或指令所在的动态共享对象(Dynamic Shared Object), 如内核、进程名、动态链接库名、内核模块名等。
-
第三列 Object ,是动态共享对象的类型。比如 [.] 表示用户空间的可执行程序、或者动态链接库,而 [k] 则表示内核空间。
-
最后一列 Symbol 是符号名,也就是函数名。当函数名未知时,用十六进制的地址来表示。
还是以上面的输出为例,我们可以看到,占用 CPU 时钟最多的是 update_blocked_averages,不过它 的比例也只有 4.71%,说明系统并没有 CPU 性能问题。 perf top 的使用你应该很清楚了吧。
perf record & perf report
perf top 虽然实时展示了系统的性能信息,但它的缺点是并不保存数据,也就无法用于离线或者后续的分析。 而 perf record 则提供了保存数据的功能,保存后的数据,需要你用 perf report 解析展示。
1
2
3
4
5
|
$ perf record # 按 Ctrl+C 终止采样
[ perf record: Woken up 1 times to write data ]
[ perf record: Captured and wrote 0.452 MB perf.data (6093 samples) ]
$ perf report # 展示类似于 perf top 的报告
|
在实际使用中,我们还经常为 perf top 和 perf record 加上 -g 参数,开启调用关系的采样,方便我们根据调用链来分析性能问题。
perf 其它使用
1
2
3
|
perf top -g -p $pid
perf record -ag -- sleep 2;perf report
|
ab
1
2
|
# 并发 10 个请求测试 Nginx 性能, 总共测试 100 个请求
$ ab -c 10 -n 100 http://192.168.0.10:10000/
|
小结
-
用户 CPU 和 Nice CPU 高,说明用户态进程占用了较多的 CPU,所以应该着重排查进 程的性能问题。
-
系统 CPU 高,说明内核态占用了较多的 CPU,所以应该着重排查内核线程或者系统调 用的性能问题。
-
I/O 等待 CPU 高,说明等待 I/O 的时间比较长,所以应该着重排查系统存储是不是出现 了 I/O 问题。
-
软中断和硬中断高,说明软中断或硬中断的处理程序占用了较多的 CPU,所以应该着重 排查内核中的中断服务程序。
碰到 CPU 使用率升高的问题,你可以借助 top、pidstat 等工具,确认引发 CPU 性能问 题的来源;再使用 perf 等工具,排查出引起性能问题的具体函数。
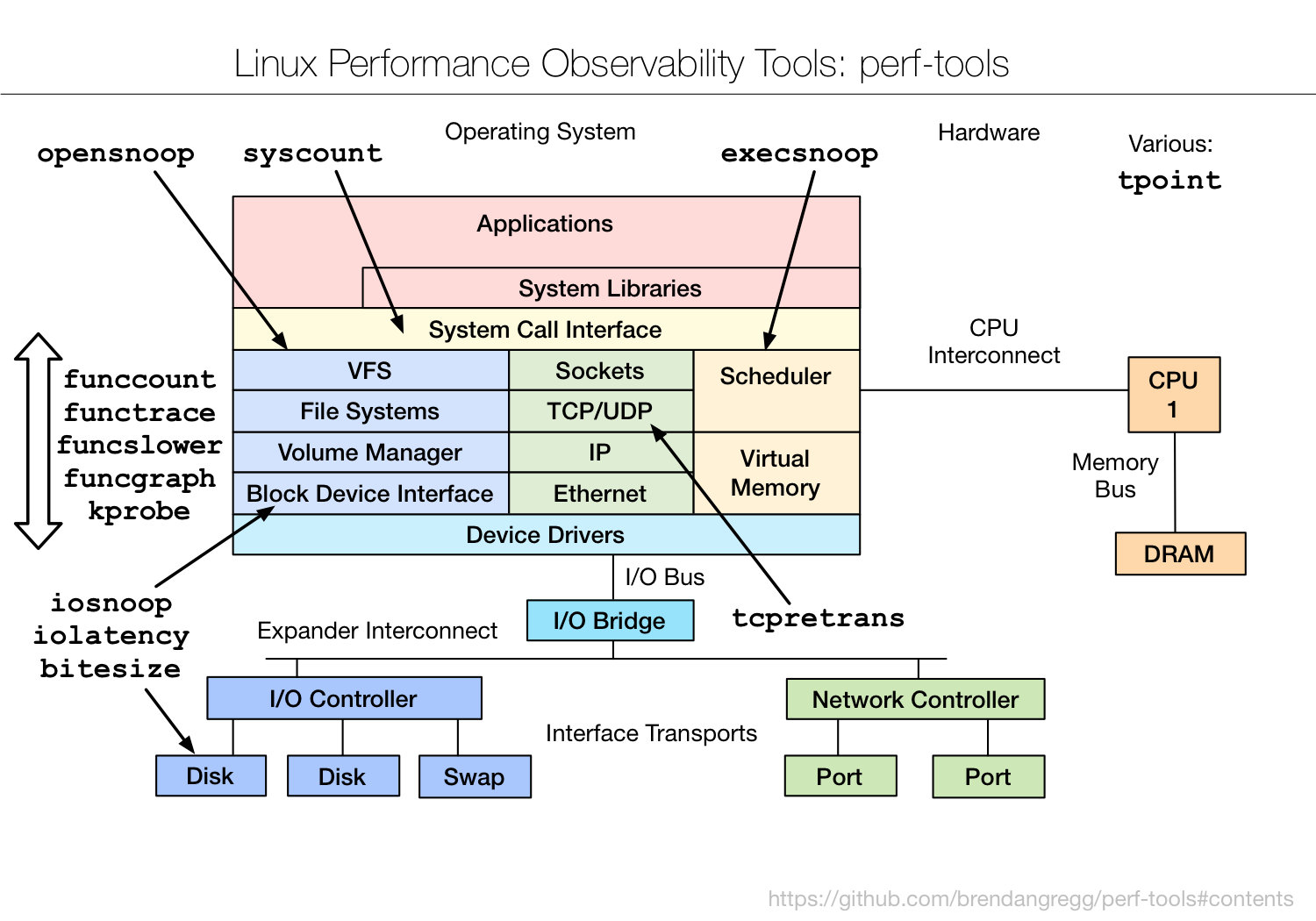
短时应用的运行时间比较短,很难在 top 或者 ps 这类展示系统概要和进程快照的工具中 发现,你需要使用记录事件的工具来配合诊断,比如 execsnoop 或者 perf top。
常见分析工具perf-tools 及相关例子